Pity Schrödinger's cat, feverishly recalling its undergraduate physics, while Mr S ponders the large in relation to the very small. Ultimately, the magnified behaviour of a fundamental particle embodies the feline's fate, and similarly, the behaviour of fundamental object-relationships determines the performance profile of a given data-structure/algorithm combination. The cost of these is often seen as insignificant, and is thereby overlooked; therefore this article is an empirical study of the temporal overheads carried by subsumption, indirection and polymorphism in C++.

|
A version of this article appeared online in association with the August 2006 edition of Dr Dobbs Journal of Programming. |
Given a class 'Obj' that supports a function 'F', it is possible to create a client class, also supporting a function 'F', such that Client::F calls Obj::F. The client class can be related to an instance of Obj by:
Theory demands that the first case should exhibit the fastest performance, because there is no pointer to de-reference in calling Obj::F. The second case should therefore be slightly slower, because of the overhead of the indirection, and the third should be slower still, because the indirection overhead is compounded by the overhead of calling F through a v-table.
Experimenting with these scenarios requires the test code to be as representative of production code as possible, without tending to any particular extreme. Moreover, no scenario should have an unfair advantage over the others. Therefore, in these tests, Obj::F is passed a single parameter (as a stab at orthogonality), and this is used in the body of F, so as to prevent the compiler from eliding the function entirely should the call it generates be inlined. The essential definitions for these scenarios are shown in Listing 1.
Note that although, in the third scenario, DerivedObj::F is not called explicitly, its body should retain the 'Attrib = Value' statement, even though this is redundant in terms of preventing inlining-based elision. This is because any test should reveal solely the time taken to traverse the various relationships between objects, and should therefore control for the execution time of the body of F. If the body of DerivedObj::F were empty then it would execute faster than Obj::F in the other two scenarios, which would weight the test data for this scenario unfairly.
// Listing 1
class Obj
{
private: unsigned Attrib;
public: void F (unsigned Value) { Attrib = Value; }
};
// Alternative definition of Obj,
// and a subclass for Scenario 3
class Obj { public: virtual void F (unsigned Value) = 0; };
class DerivedObj : public Obj
{
private: unsigned Attrib;
public: virtual void F (unsigned Value) { Attrib = Value; }
};
class Client
{
// Scenario 1
private: Obj Instance;
public: void F (unsigned Value) { Instance.F (Value); }
// Scenario 2
private: Obj *Instance;
public: void F (unsigned Value) { Instance->F (Value); }
// Scenario 3
private: Obj *Instance; // Base-type pointer to
// instance of DerivedObj
public: void F (unsigned Value) { Instance->F (Value); }
};
Obviously, this does not reflect production code entirely, as classes frequently possess more than one attribute, and an equally reasonable definition of Client could prefix the definition of Instance with another object, as Listing 2 illustrates.
This is significant, at least in C++, because the language standard guarantees that the in-memory layout of an object follows the order of definition in the source code. Given this, the address of Instance in all three scenarios in Listing 1 will be the same as the address of Client. However, for the equivalent definitions of Client, as in Listing 2, the address of Instance will be at a positive offset to the address of the parent object. This means that just prior to the call to Instance.F () the CPU must add that offset to the Client's 'this' pointer, in order to determine the correct address for Instance. This is evident in the machine-instruction sequences that the compiler generates, as Listing 3 demonstrates.
// Listing 2
class Client
{
private: int Attrib;
Obj Instance;
...
};
Clearly, the two sequences are virtually identical; except for the LEA instruction in the second listing. This should take extra time to complete, meaning that calling F should be slightly slower for the definition of Client in Listing 2 than for the definition in Listing 1. Given that this 'preceding-attribute' variant applies to all three scenarios, there are, in fact, six test-cases that should be examined.
Listing 3
'Instance' not preceded 'Instance' preceded
by 'Attrib' by 'Attrib'
mov -024h[EBP],EAX mov -024h[EBP],EAX
lea EBX,-028h[EBP] lea EBX,-02Ch[EBP]
mov -010h[EBP],EBX mov -010h[EBP],EBX
xor ESI,ESI xor ESI,ESI
mov -0Ch[EBP],ESI mov -0Ch[EBP],ESI
mov -8[EBP],EBX lea EAX,4[EBX]
mov -4[EBP],ESI mov -8[EBP],EAX
mov [EBX],ESI mov -4[EBP],ESI
mov [EAX],ESI
Note that a corollary to this is that Listing 3 is proof of a performance micro-optimisation technique. To wit: when implementing subsumptive relationships, the most temporally popular object should be defined first in the parent class's definition — although the converse does not follow, as defining the least temporally popular object last will simply entail the addition of a greater offset, not a greater number of additions.
It does follow, however, that the technique can be applied recursively. I.e. should the subsumed object itself contain an oft-used object then this third object should also be defined at the beginning of its parent class, as Listing 4 demonstrates.
In this case the value of the 'this' pointer for the call to A::F will be the same as for the call to B::F, which will be the same as the call for C::F. If InstanceOfA and InstanceOfB are both temporally popular, then their positions as the first objects in their parent-class definitions should — in the ideal case — maximise performance. Note also that this effect, especially when conjoined with inlining, should magnify as you continue to subsume recursively.
// Listing 4
class A { public: void F () { ... } };
class B
{
private: A InstanceOfA;
// Other attributes...
public: void F () { InstanceOfA.F (); }
};
class C
{
private: B InstanceOfB;
// Other attributes...
public: void F () { InstanceOfB.F (); }
};
The test code was compiled using Digital Mars v8.38 — employing the RDTSC machine-instruction to measure the number of machine cycles consumed[1] — and was run on a Pentium MMX and PIII, in order to reveal the difference between older and relatively younger CPU-designs. Cache-based operations alone were sampled, with RTTI and exception handling disabled, and function inlining being the only optimisation. The (rather surprising) results, adjusted for the test-harness overhead, are shown in the table, and the chart below. Note that all Standard Deviations, where relevant, were minimal. Note also that the trend-lines in the chart are a purely intuitive (and probably incorrect) guess at what the reality may be, given the unusual nature of the test results.
| Subsumption | Subsumption with Offset |
Indirection | Indirection with Offset |
Indirection to Polymorph |
Indirection to Polymorph, with Offset |
||
| P-MMX | High | 4.5 | 4.5 | 5.5 | 6.5 | 10.5 | 11.5 |
| Low | 2.5 | 3.5 | 5.5 | 4.5 | 10.5 | 9.5 | |
| Mean | 3.5 | 4.0 | 5.5 | 5.1 | 10.5 | 10.1 | |
| PIII | High | 6.0 | 6.0 | 8.0 | 7.0 | -30.0 | -30.0 |
| Low | 6.0 | 6.0 | 8.0 | 7.0 | -30.0 | -30.0 | |
| Mean | 6.0 | 6.0 | 8.0 | 7.0 | -30.0 | -30.0 | |
In isolation, the trend in the MMX data conforms roughly to theory, where more machine cycles are consumed when traversing more complex relationships. Although, surprisingly, indirection-with-offset is actually slightly faster than plain indirection; and the trend reverses similarly in the polymorphism-with-offset case. Note also that the High, Low and Mean cycle-counts in the PIII data are all equal, which is not the case with the MMX.
What runs entirely contrary to expectation, however, is that the PIII consumes more machine cycles than the MMX in the first four scenarios, despite its more advanced architecture. More surprising still are the polymorphic tests, which consume fewer cycles than does execution of the test harness on its own (which is why they are not depicted on the chart). What are we to make of this?
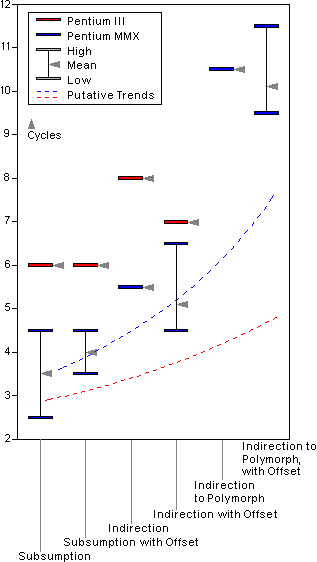
These seemingly anomalous results expose the problem with timing fundamental relationships precisely on modern hardware, in that the minimalism of the test regimen falls foul of features such as pipelining and parallel processing. For example, the compiler clearly generates longer and more complex instruction-sequences for the polymorphic scenarios, which, along with the instructions for the core test-harness, would suggest a higher cycle-count overall.
Yet this is meat and drink for a voracious processor; although the test harness uses CPUID initially, so as to force completion of out-of-order operations, this instruction can still be prefetched, pipelined, executed in parallel, and out of order with the timing instructions that follow ...along with the sequence under test. This is why the polymorphic scenarios are quicker on the PIII than the test harness alone. Conversely, the more primitive scenarios deny the better CPU a chance to really flex its muscles, which is why it scores worse than the MMX in these tests. The corollary to this is that more primitive machines should be more theory-conformant — the irony being that pre-Pentium CPUs did not support RDTSC, despite years of wishing on the part of developers.
Given this, the results do not mean that polymorphic calls really are faster than the subsumptive or indirected variety. Moreover, the test regimen does not reflect the complex and arbitrary nature of 'real' code, as it samples only cache-based execution of a function that does nothing of significance. In real applications, subsumption and indirection permit the massive benefits of function inlining, and conversely, polymorphic scenarios fare considerably worse, because virtual calls cannot be inlined.
It follows that orthogonal metrics for the fundamental relationships (on modern hardware) can only be gathered by testing an orthogonal application. Yet the complexity of real code precludes absolutely precise measurements, thus forcing the minimalism adopted here. Moreover, the arbitrary nature of any given application renders the concept of 'orthogonal' purely hypothetical. It would seem, therefore, that advances in computing technology have yielded a situation akin to quantum mechanics — our theoretical model is logical, exact and sound, yet it cannot be mapped reliably to the macroscopic world that it generates.
Nevertheless, and however indeterminate our modelling-quanta may be when under the chronoscope, subsumption should always be preferred over indirection, which should always be preferred over indirection to polymorphic types. The more primitive the relationship the stronger the design guarantees that it offers — and what cautious cat would sniff at that, given this slippery issue of performance?
[1] Testing Times — Resolving Temporal Costs at the Level of Individual Machine-Cycles
Richard Vaughan
Dr Dobbs Journal of Programming (online) June 2006